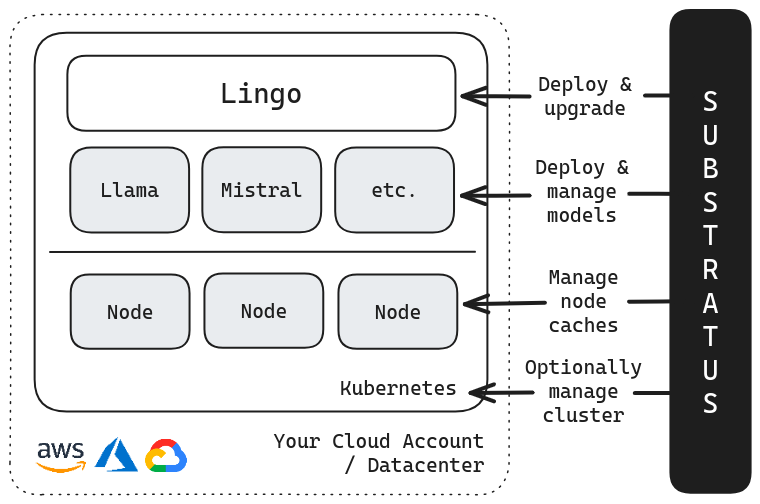
Fully Managed Private LLMs
Serve Open Source or custom LLMs swiftly and securely. Save time and money with an autoscaling LLM serving stack in your private environment (on-prem & cloud).
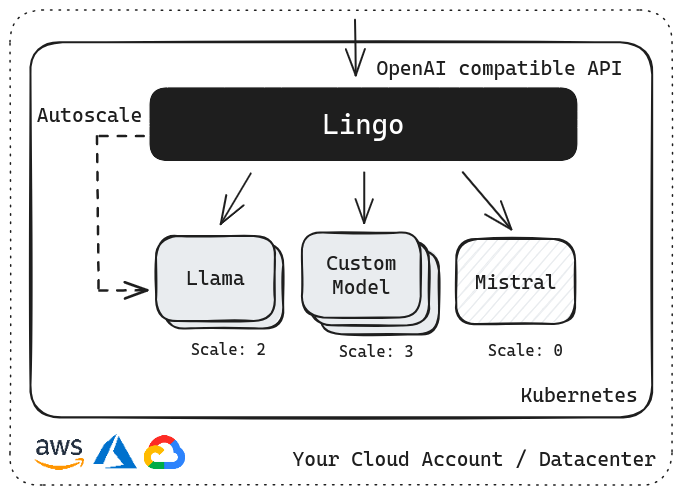
Serve LLMs in Minutes
We'll get you the latest OSS LLMs up and running in minutes.
Autoscaling LLMs
Scale from 0 to infinity (GPU capacity permitting) to efficiently utilize GPU resources.
Fully Managed
We manage the entire LLM serving stack for you, including the models.
Open Source, no lock-in
Our LLM Serving stack is based on Lingo OSS. Switch to managing yourself at any time.
Batch Inference Ready
Auto scale up to 100s of GPUs to finish the job in hours and then back to 0.
Your infra
Run on your own cloud account or K8s cluster. Save costs and protect data.
What our early adopters say
Saving $XXXX per batch job and faster LLM adoption
Substratus helped us accelerate our LLM adoption for doing large scale summarization. Our use case involved doing batch inference on more than a million documents in less than a day. Substratus deployed Lingo in our GCP project and allowed us to save thousands of dollars on each batch inference job.
Olivier R. - CTO at TryTelescope.ai
Accelerate your LLM journey today
Run LLMs in production in hours instead of weeks.
Focus on utilizing LLMs for your business instead of managing infrastructure.