Private RAG with Lingo, Verba and Weaviate
Looking to deploy RAG on Kubernetes? Check out KubeAI, providing private Open AI on Kubernetes.
Note: This tutorial was originally written for Lingo, but Lingo has been replaced by KubeAI. If you are looking for a similar setup, check out the KubeAI with Weaviate tutorial
In this post you will setup a Retrieval-Augmented Generation stack on top of Kubernetes. You will deploy the Verba application from Weaviate and wire it up to Lingo which provides local LLM inference and embedding servers. Now you can take full control over your data and models.
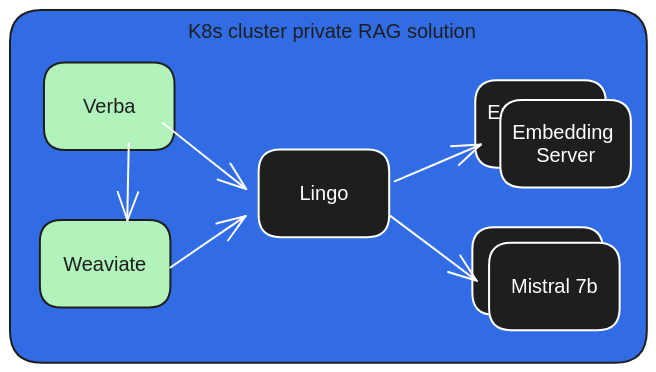
You will use the following components:
- Verba as the RAG application
- Weaviate as the Vector DB
- Lingo as the model proxy and autoscaler
- Mistral-7B-Instruct-v2 as the LLM
- STAPI with MiniLM-L6-v2 as the embedding model
K8s cluster creation (optional)
You can skip this step if you already have a K8s cluster with GPU nodes.
Create a GKE cluster with a CPU and 1 x L4 GPU nodepool:
bash <(curl -s https://raw.githubusercontent.com/substratusai/lingo/main/deploy/create-gke-cluster.sh)
Make sure you review the script before executing!
NOTE: Even though this script is for GCP, the components here will work on any Kubernetes cluster (AWS, Azure, etc). Reach out on discord if you get stuck!
Installation
Now let's use Helm to install the components on your K8s cluster.
Add the required Helm repos:
helm repo add weaviate https://weaviate.github.io/weaviate-helm
helm repo add substratusai https://substratusai.github.io/helm
helm repo update
Deploy Mistral 7b instruct v2
Create a file named mistral-v02-values.yaml with the following content:
model: mistralai/Mistral-7B-Instruct-v0.2
replicaCount: 1
# Needed to fit in 24GB GPU memory
maxModelLen: 15376
servedModelName: mistral-7b-instruct-v0.2
chatTemplate: /chat-templates/mistral.jinja
env:
- name: HF_TOKEN
value: ${HF_TOKEN}
resources:
limits:
nvidia.com/gpu: 1
deploymentAnnotations:
lingo.substratus.ai/models: mistral-7b-instruct-v0.2
lingo.substratus.ai/min-replicas: "1" # needs to be string
lingo.substratus.ai/max-replicas: "3" # needs to be string
Export your HuggingFace token (required to pull Mistral):
export HF_TOKEN=replaceMe!
Install Mistral-7b-instruct-v2 using the token you exported in previous step:
envsubst < mistral-v02-values.yaml | helm upgrade --install mistral-7b-instruct-v02 substratusai/vllm -f -
Installing Mistral can take a few minutes. Kubernetes will first try to scale up the GPU nodepool and then the model will be downloaded and loaded into memory.
Use the following commands to view the logs:
kubectl get pods -l app.kubernetes.io/instance=mistral-7b-instruct-v02 -w
kubectl logs -l app.kubernetes.io/instance=mistral-7b-instruct-v02
IMPORTANT: You will be paying for the GPU usage while the model is running,
because min scale is set to 1.
Make sure to uninstall the Helm release (mistral-7b-instruct-v02) when you are done using the model!
Deploying Embedding Model Server
We are going to deploy STAPI - Sentence Transformers API, an embedding model server with an OpenAI compatible endpoint.
Create a file called stapi-values.yaml with the following content:
deploymentAnnotations:
lingo.substratus.ai/models: text-embedding-ada-002
lingo.substratus.ai/min-replicas: "1" # needs to be string
model: all-MiniLM-L6-v2
replicaCount: 0
Install STAPI using the values file you created:
helm upgrade --install stapi-minilm-l6-v2 substratusai/stapi -f stapi-values.yaml
Deploy Lingo
Lingo provides a unified endpoint for both the LLM and embedding model. It proxies requests and autoscales the models based on load. It can be thought of as a OpenAI drop-in replacement for running inference locally.
Install Lingo with Helm:
helm upgrade --install lingo substratusai/lingo
You can reach Lingo from your local machine by starting a port-forward:
kubectl port-forward svc/lingo 8080:80
Test out the embedding server with the following curl command:
curl http://localhost:8080/v1/embeddings \
-H "Content-Type: application/json" \
-d '{
"input": "Lingo rocks!",
"model": "text-embedding-ada-002"
}'
Mistral can be called via the "completions" API:
curl http://localhost:8080/v1/completions \
-H "Content-Type: application/json" \
-d '{"model": "mistral-7b-instruct-v0.1", "prompt": "<s>[INST]Who was the first president of the United States?[/INST]", "max_tokens": 40}'
Deploy Weaviate
Let's deploy Weaviate with the OpenAI text2vec module and a single replica.
Create a file called weaviate-values.yaml with the following content:
modules:
text2vec-openai:
enabled: true
apiKey: 'thiswillbeignoredbylingo'
service:
type: ClusterIP
Install Weaviate using the values file you created:
helm upgrade --install weaviate weaviate/weaviate -f weaviate-values.yaml
Deploying Verba
Verba is the RAG application that utilizes Lingo and Weaviate.
Create a file called verba-values.yaml with the following content:
env:
- name: OPENAI_MODEL
value: mistral-7b-instruct-v0.2
- name: OPENAI_API_KEY
value: ignored-by-lingo
- name: OPENAI_BASE_URL
value: http://lingo/v1
- name: WEAVIATE_URL_VERBA
value: http://weaviate:80
We set the OPENAI_BASE_URL to the Lingo endpoint and WEAVIATE_URL_VERBA to the Weaviate endpoint.
This will configure Verba to call Lingo instead of OpenAI, keeping all data local to the cluster.
Install Verba from Weaviate using the values file you created:
helm upgrade --install verba substratusai/verba -f verba-values.yaml
Usage
Now that everything is deployed, you can try using Verba.
The easiest way to access Verba is through a port-forward (don't forget to terminate the previous port-forward command first):
kubectl port-forward service/verba 8080:80
Now go to http://localhost:8080 in your browser. Try adding a document and asking some relevant questions.
For example, download a PDF document about Nasoni Smart Faucet here.
Upload the document inside Verba and ask questions like:
- How did they test the Nasoni Smart Facet?
- What's a Nasoni Smart Facet?
Conclusion
You now have a fully private RAG setup with Weaviate and Lingo. This allows you to keep your data and models private and under your control. No more expensive LLM calls or OpenAI rate limits. 🚀
Like what you saw? Give Lingo a star on GitHub ⭐